The Role of Data in Future Technologies
Discover how data shapes future technologies through real life examples, step by step strategies, and lessons from hands on projects. Learn practical tips to leverage data effectively in evolving tech.

Main Highlights Regarding the Role of Data in Future Technologies
Data is the real backbone of future technologies, not AI or automation alone
Clean, well structured data matters more than large volumes of raw data
Poor data decisions can silently break performance, trust, and scalability
Data driven systems improve accuracy, speed, and user experience over time
Ethical data handling is becoming a core requirement, not an optional feature
Real world testing and feedback matter as much as analytics dashboards

Why Data Became My Biggest Bottleneck
I used to believe that powerful software came from better code and stronger servers. That belief stayed with me until one of my projects started failing in ways I couldn’t explain. Features worked perfectly during testing, yet real users experienced slow responses, inaccurate outputs, and inconsistent behavior.
After weeks of debugging, I realized the problem wasn’t the technology stack at all it was the data feeding the system.
That experience forced me to rethink how data actually shapes future technologies. Once I fixed my data workflows, everything else started working the way it was supposed to. This blog is based on that real shift in my thinking and practice.

Why Data Is the Real Engine Behind Future Technologies
When people talk about future technologies, they usually focus on artificial intelligence, automation, or smart devices. From my experience, those are only the visible parts. What actually drives these technologies is data quality, availability, and interpretation.
Every modern system depends on data for:
Decision making
Personalization
Performance optimization
Predictive behavior
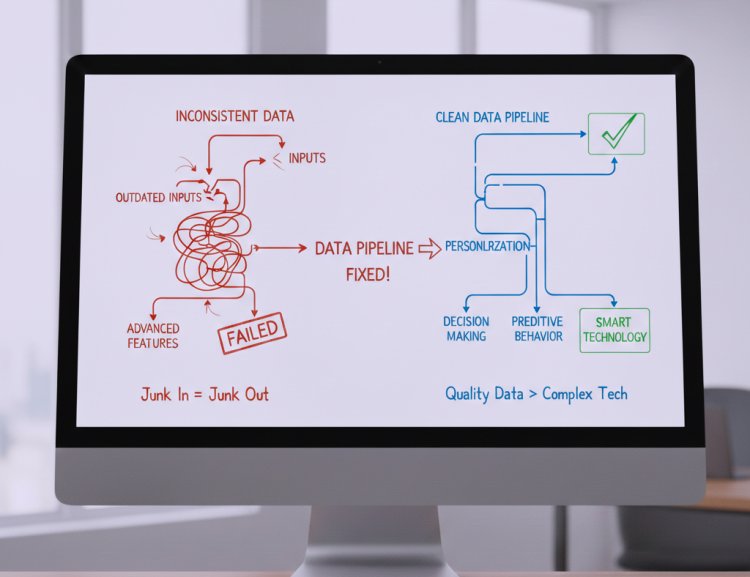
I’ve worked on systems where advanced features failed simply because the data feeding them was inconsistent or outdated. Once the data pipeline was fixed, the same technology suddenly felt “smart.”
That’s when I understood: future technologies don’t improve on their own data makes them improve.
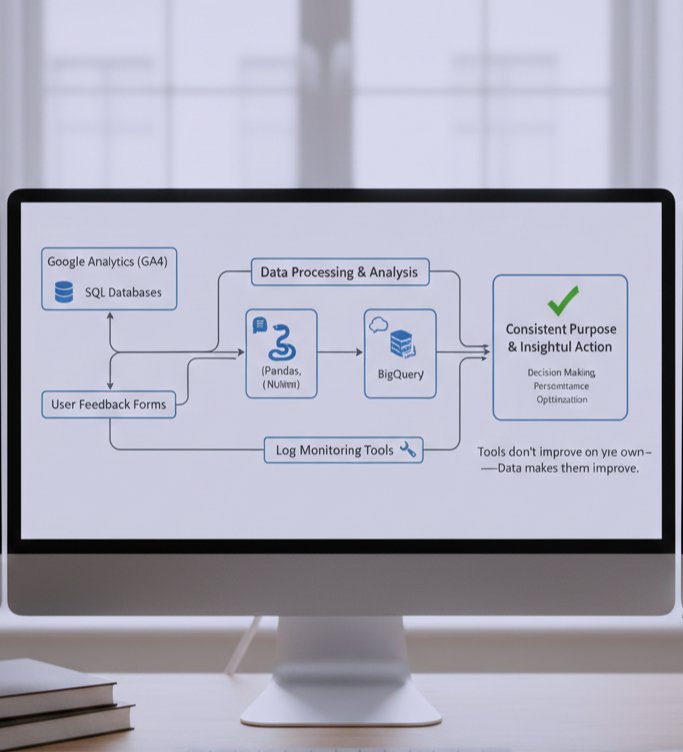
Tools I’ve Personally Used While Working With Data
Instead of theory, here are tools I’ve actually used in real projects:
Google Analytics (GA4) tracking real user behavior
SQL databases organizing structured data efficiently
Python (Pandas, NumPy) cleaning and analyzing datasets
BigQuery handling large scale data processing
Log monitoring tools detecting performance issues
User feedback forms balancing numbers with human insight
The biggest lesson here wasn’t about tools it was about using them consistently and with a clear purpose.
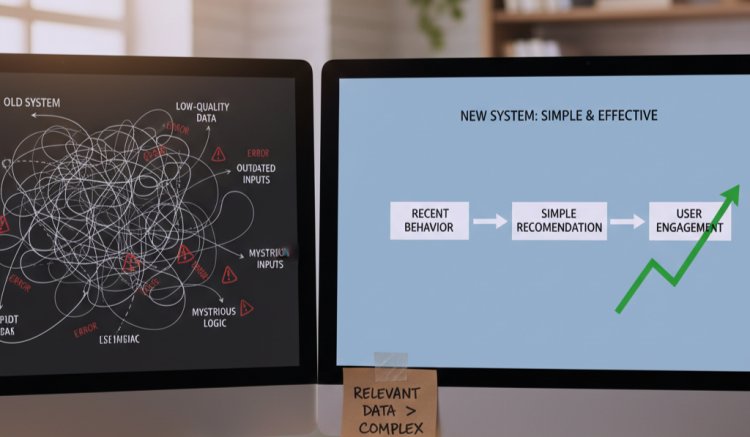
How Better Data Fixed a Broken Feature
In one project, I built a feature meant to “predict” what users needed next. On paper, it looked impressive. In reality, users ignored it.
Instead of redesigning the UI, I looked at the data:
Click patterns
Session duration
Drop off points
The data showed users didn’t trust the recommendations. The system was technically correct but contextually wrong.
What I changed:
Removed low quality data sources
Focused on recent user behavior only
Added simple explanations for recommendations
The result was a noticeable increase in engagement without adding complexity. That’s when I learned that relevant data beats complex logic every time.
Step by Step Guide: How I Now Use Data in Future Focused Projects
Step 1: Start With the Decision, Not the Data
Before collecting anything, I ask:
What decision will this data help me make?
What action will change because of it?
This avoids unnecessary data collection.
Step 2: Collect Only Meaningful Signals
I ignore vanity metrics and focus on:
User intent
System errors
Performance trends

Step 3: Clean the Data Ruthlessly
This is where most projects fail. I spend time fixing:
Missing values
Duplicate records
Inconsistent formats
Clean data alone has improved performance more than any algorithm change I’ve made.

Step 4: Test on Small Samples
Before committing to large scale implementation, I always test my insights on smaller datasets. This step is crucial because it allows me to identify errors, inconsistencies, or misleading patterns early, without wasting time or resources on full scale projects.
For example, when I was analyzing user behavior data for a software update, I first ran tests on a subset of 5 to 10% of the data. This helped me spot anomalies that would have gone unnoticed if I jumped straight into the complete dataset. Testing on smaller samples also allows for faster iterations I can tweak algorithms, adjust data cleaning methods, or refine predictive models more efficiently.
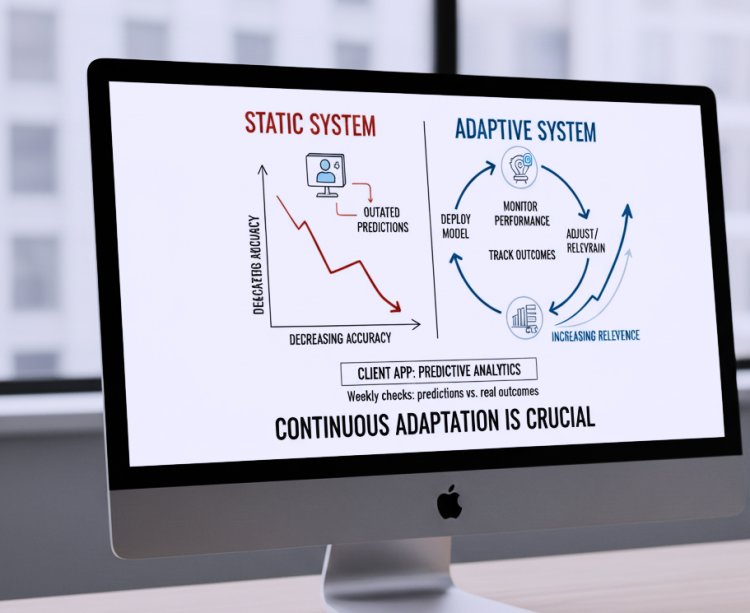
Step 5: Monitor and Adjust Continuously
Once the model or system is applied at scale, the work doesn’t stop. Future technologies and user behaviors evolve constantly, and static systems quickly become outdated. I make it a point to continuously monitor performance, track outcomes, and adjust algorithms as needed.
For instance, after deploying a predictive analytics model for a client’s app, I set up weekly performance checks to see how predictions matched real outcomes. Whenever discrepancies appeared, I adjusted the model or retrained it with new data.
What I Got Wrong the First Time (And What I Learned)
Early on, I believed more data meant better results. I collected everything logs, clicks, timestamps without structure.
The outcome:
Slower processing
Confusing insights
Higher infrastructure costs
The fix:
Reduced data inputs
Focused on high confidence signals
Scheduled regular data reviews
After simplifying, accuracy improved and maintenance became easier. That mistake taught me a critical lesson: discipline beats volume in data strategy.

Real Life Feedback Changed How I Trust Data
In one system, analytics showed everything was “working.” But users complained it felt unreliable.
When I combined:
Quantitative metrics
User feedback
Error logs
A different picture emerged. The system was technically correct but emotionally frustrating. That’s when I learned that data without context can be misleading.

How I Keep Data Systems Reliable
|
Task |
Frequency |
Reason |
|
Data validation |
Weekly |
Prevents silent errors |
|
Dataset cleanup |
Monthly |
Reduces noise |
|
Privacy review |
Quarterly |
Maintains user trust |
|
Performance monitoring |
Continuous |
Keeps systems responsive |
Data Ethics and Trust in Future Technologies
As technologies become more data driven, trust becomes fragile. From my experience:
Clear data usage policies increase adoption
Transparency reduces resistance
Secure handling prevents long term damage
Misusing data doesn’t just harm users it harms credibility.

Tips From My Experience
From my experience working with data driven projects, I learned that having lots of data isn’t enough. The real value comes from how you use it. Start by testing your models on smaller datasets this helps you catch mistakes early without wasting time or resources. Make sure to clean and organize your data properly; messy or inconsistent data can lead to wrong conclusions.
I also found that observing patterns is important, but don’t obsess over every anomaly. Sometimes unusual results are just noise, and stressing over them can slow you down. Always document your process what works, what fails, and how you fixed issues. This not only makes troubleshooting easier but also speeds up future projects.

What I’d Tell My Past Self
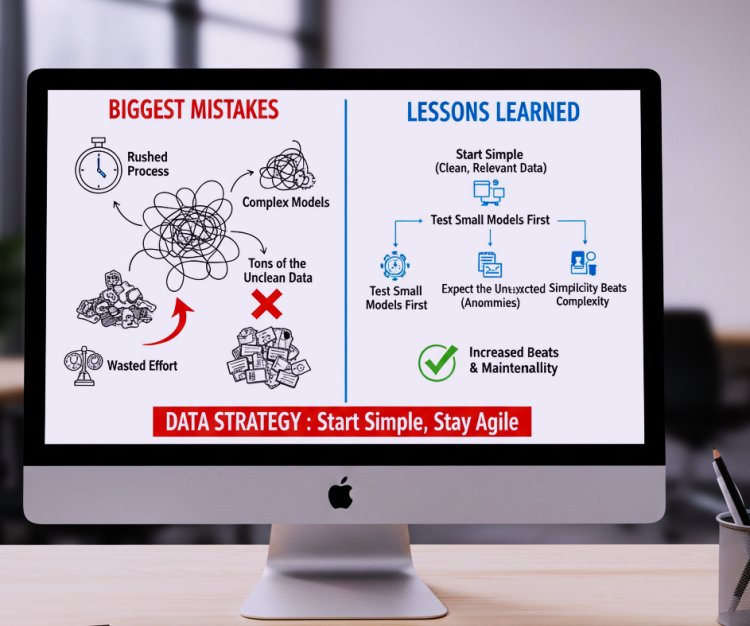
Looking back, I realize the biggest mistakes I made were trying to rush into collecting tons of data and building complex models without understanding the core problem. If I could go back, I’d start with clean, relevant data and make sure it truly reflects the user behavior or system I’m analyzing. I’d also test small models first before scaling anything this saves time, highlights what actually works, and prevents wasted effort on approaches that don’t deliver.
Another thing I’d stress to myself is to expect the unexpected. Anomalies, edge cases, and unusual patterns aren’t just rare they happen all the time. Planning for these early prevents surprises later. At the same time, I’d remind myself that simplicity often beats complexity; over engineered solutions can be fragile, hard to maintain, and confusing for the team.
Common Questions About the Role of Data in Future Technologies
1. Why is data considered the backbone of future technologies?
Data drives decisions, powers AI algorithms, and enables personalization. Without accurate data, even advanced technology fails to deliver results.
2. Does more data always mean better outcomes?
Not necessarily. Quality, relevance, and structure of data matter more than sheer volume. Clean, meaningful datasets outperform massive, messy ones.
3. How does data improve software performance?
By enabling predictive insights, reducing errors, optimizing workflows, and enhancing user experience. Systems react faster and smarter when backed by reliable data.
4. What common mistakes do people make with data?
Collecting unnecessary data, ignoring data cleaning, and failing to validate sources. These issues slow performance and can mislead decision making.
5. How often should data be reviewed or updated?
Data should be reviewed continuously or at least periodically, depending on system complexity and user behavior changes. Outdated data can reduce accuracy and reliability.
6. How can small projects benefit from data driven approaches?
Even small scale projects improve efficiency and decision making when they focus on relevant, high quality data rather than trying to collect everything.
What's Your Reaction?
















